Data Pipeline Automation: 5 Benefits and 7 Steps to Start
 Admin
Admin



In this information age, companies generate massive amounts of data every other second. Manually handling this data is time-consuming, error-prone, and hardly efficient. Where conventional data processing is concerned, it has generally lagged in the growing complexity and volume of information, giving rise to delays and loss of opportunities.
Automating data pipelines provides that opportunity by getting data from ingestion to analysis with minimal human intervention. Automation ensures that human errors are avoided, processes are more efficient, and real-time insights are more accurate. Organizations lagging in automation are likely to miss opportunities to turn their data into a core source of decision-making and innovation.
In this guide, we will cover the most relevant types of data pipes and the key benefits of automation, best practices in the implementation, and factors that affect the successful outcome. By the end, you will be aware of how automating data processes can improve efficiency, lessen manual work, and yield a good base for future technologies like AI and machine learning.
What Are Data Pipelines?
A data pipeline is a structured session whereby data are processed crosswise in a system with efficacious transformation, processing, and storage. The process involves multiple sequential steps, whereby the outcome of one step will serve as the basis of the next step. Data ingestion, transformation, processing, and storage are some of the steps involved.
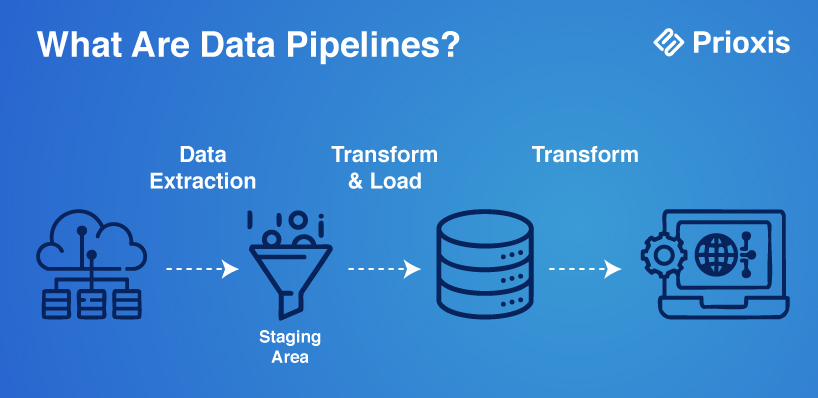
There are three major components of data pipelines:
Source – Origin of the data (databases, APIs, logs, etc).
Processing Steps – Transformation, cleansing, and modifications performed on the data.
Destination or Sink – Final storage or system for the processed data.
From primary work where data transmits at a point to a destination, it can be complicated by collecting data from several sources and then performing some transformations for analytical or business intelligence purposes. Automated pipelines provide a reliable, scalable, and efficient method for handling the massive amounts of structured and unstructured data that businesses have nowadays.
What is Data Pipeline Automation?
Data pipeline automation is a technique for the automated and systematic transfer of data from one system to another or between separate platforms or technologies. Manual data transfers are eliminated to achieve excellence in scalability, accuracy, and efficiency.
Automated data pipelines ingest, process, and transform data from different sources and then deliver it to business applications, analytical software, or storage systems. Compared to manual data handling, automated data processing will ensure better data quality, reduce errors, and cost- and time-effectiveness.
A normal automated data pipeline comprises a few fundamental phases:
Data Ingestion – collecting data from multiple sources, such as databases, APIs, applications, and microservices.
Data Processing – Cleaning, validating, and transforming data so that it is structured and useful.
Data Storage – Storing processed data in a database, data warehouse, or cloud storage for future use.
Data Analysis – Utilizing techniques like machine learning and predictive analytics to extract meaningful insights.
Data Visualization – The visualization of data in the form of dashboards, reports, and alerts for effective decision-making.
By automating these IT processes, firms can ensure consistent data flow, improve business efficiency, and offer real-time insights, hence making data-driven decision-making easier.
Types of Data Pipeline Architectures
This architecture for data pipeline describes how the data moves from its source to destination, efficient in extracting, transforming, and delivering data. Organizations can then map their data pipeline architecture depending on their specific needs.
1. Batch Data Pipeline
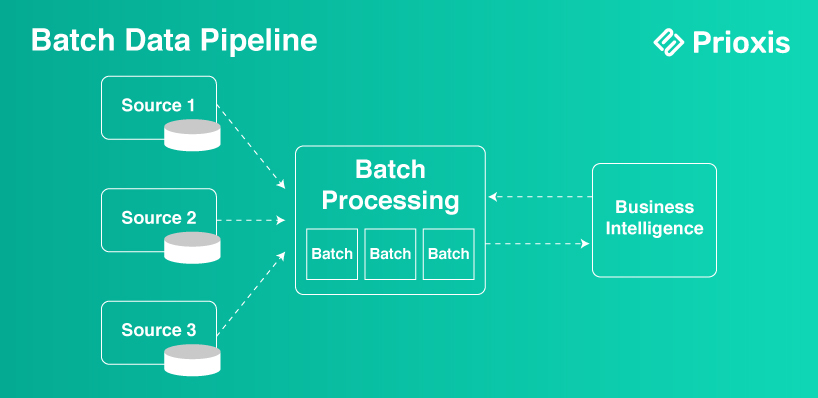
The pipeline systems for batch data process the particular data in volumes, so it is at a specific interval. It is also used with classic data analysis and business intelligence (BI)-oriented software to process historical data. All of the data set is first collected and processed before being stored for analysis. The time taken for execution varies from minutes to days. It is better for batch processing to handle very large data but is not suitable for instant insights.
2. Streaming Data Pipeline
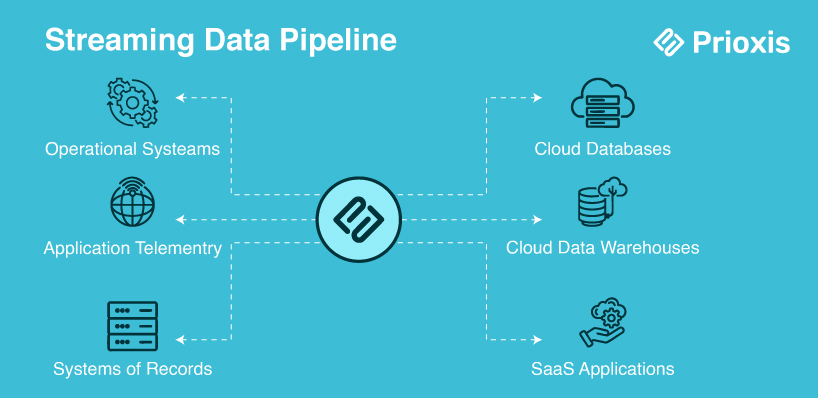
Streaming Data pipelines simply process real-time data; they attend to steady flows of data within seconds or milliseconds. Unlike batch processing, however, new data comes, and at the same time, streaming analytics provides up-to-date reports as they come, making it a requirement for industries that desire immediate decision-making as an application of such architecture in real-time monitoring of fraud detection and infrastructure performance.
3. Change Data Capture (CDC) Pipeline
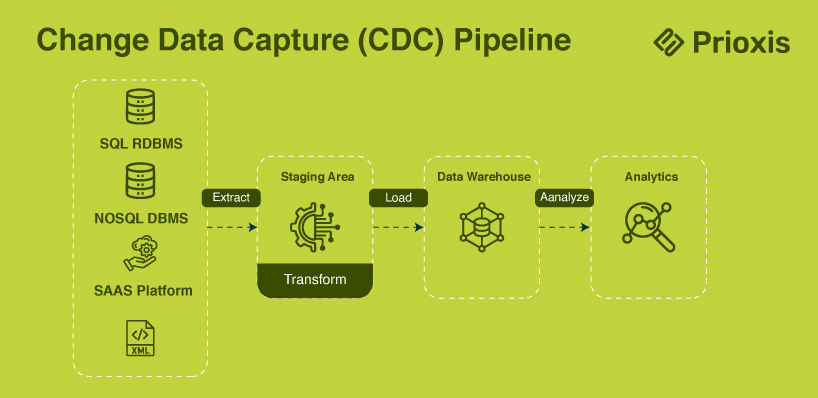
Change Data Capture pipelines are a specialized kind of streaming pipeline whose primary use is in relational databases. Unlike other streaming pipelines, which transfer whole datasets, a CDC pipeline is only going to detect and replicate changes to data since the last sync. This architecture plays an important role in ensuring consistency among several systems and is widely used with cloud migrations and big data refresh processes.
Benefits of Automating Data Pipelines
Data pipeline automation simplifies data movement and processing, presenting businesses with numerous benefits. Some of the major advantages are:
1. Enhanced Efficiency
Data pipeline automation eliminates human intervention, minimizing errors and accelerating data processing. This makes data move flawlessly between systems, improving overall operational efficiency.
2. Improved Data Quality
Just by automating data validation, cleaning, and transformation, businesses can ensure higher accuracy in their respective data as well as consistency. They eliminate possible inconsistencies and errors caused by handling the same through manual processing.
3. Scalability
It's more than capable of automatically processing any bulk of data that continues to pile up and grow, accommodating itself to the respective business demand expansions without much human intervention. Quite useful for organizations dealing with big data and real-time analysis. Requirement analysis: Data Definition requirement.
4. Cost Reduction
Decreasing manual data management reduces operational expenses. Automated pipelines also maximize cloud storage and computing resources, which means businesses pay only for what they consume.
5. Productivity Boost
With repetitive work done by automation, data teams can concentrate on strategic projects such as data analytics and AI insights, resulting in improved decision-making and innovation.
Hindrances in Data Pipeline Automation
Though the automation of data pipelines has numerous advantages, companies are usually confronted with several implementation challenges. Some of the most important obstacles are as follows:
1. Data Quality Issues
Pipelines do not get automatically fixed with data inconsistencies, missing values, or wrong formats. Low-quality data can cause incorrect insights, so it is crucial to have robust validation and cleansing processes in place.
2. Integration Complexities
Most organizations have multiple sources of data, platforms, and legacy systems. Integrating these systems seamlessly is difficult as they might need to be extensively customized for different formats, APIs, and protocols.
3. High Initial Costs and Complexity
Implementing an automated data pipeline involves a heavy upfront investment in tools, infrastructure, and talent. Companies might not have the budget or expertise to create and manage strong pipelines.
4. Security and Compliance Challenges
Processing sensitive business and customer information in automated pipelines demands rigorous security controls and data protection regulation compliance. Maintaining encryption, access control, and auditability can be challenging, particularly in heavily regulated sectors.
How to Create an Automated Data Pipeline?
Creating an automated data pipeline assumes a well-defined approach that helps in ensuring smooth and efficient data flow from source to destination while taking care of quality and reliability. This is a quick presentation of the steps to be followed in building an automated data pipeline.
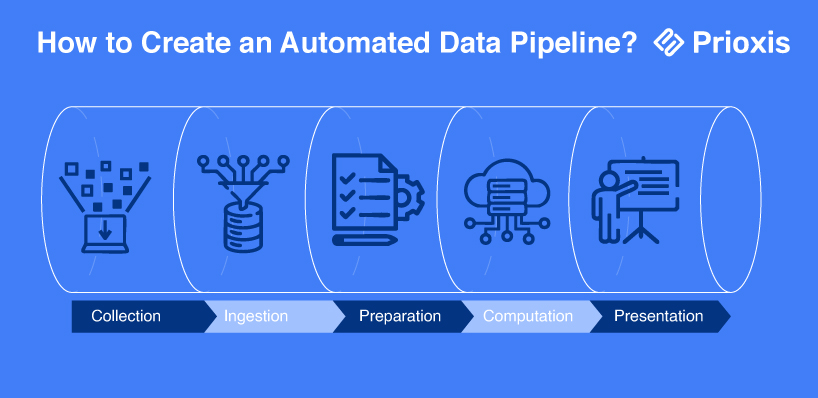
1. Define the Objectives
Before building the pipeline, set up the why and what. Am I automating ETL? Do I want to work with real-time analytics or with batch processing? Set the objectives so that they help determine the architecture.
2. Identifying the Data Source
Identify the origin of the data. Is it from databases, APIs, cloud storage, IoT devices, or third-party applications? Consistency and compatibility of data should be maintained across all sources.
3. Design the Data Pipeline Architecture
Pick a suitable architecture-batch, streaming, or Change Data Capture (CDC)-depending on the requirements of the business. Also, defines the movement of data from ingestion to transformation, storage, and consumption.
4. Data Ingestion
Setting up mechanisms for data ingestion to pull data from various sources or received. These could be through API calls, database queries, event triggers, and scheduled extraction jobs.
5. Deployment
Deploy the pipeline using automation tools like Apache Airflow, AWS Data Pipeline, or those provided by the cloud service. Ensure that the system is optimized for scalability, security, and fault tolerance.
6. Monitoring and Maintenance
Provide for continuous monitoring aimed at detecting failures, bottlenecks, or inconsistencies. Maintain performance by including logging, alerting, and auto-recovery mechanisms.
7. Documentation
Document all structures of the pipeline, data flow, dependencies, and troubleshooting methods. This makes maintenance easier and increases the probability of a seamless transition for any future development.
Use Cases of Data Pipelines
The following are some representative use cases.
- Real-Time Analytics for Business Insights
With streaming data pipelines, businesses process real-time data coming from IoT devices, social media, and customer interaction. Such timely decision-making might comprise changes to pricing in real-time, fraud detection, or personalized marketing campaigns.
- Data warehousing and business Intelligence
To integrate data from various sources, organizations store them in data warehouses such as Snowflake, Redshift, or BigQuery. An automated pipeline ensures that data is ingested, transformed, and reported on business intelligence and analytics tools in a timely and accurate manner.
- Machine Learning and AI Model Training
Data pipelines automate the collection, cleaning, and transformation processes for the training dataset for AI and machine learning models. This ensures that data scientists will have access to trustworthy and current data that support the enhancement of accuracy and predictions.
- Cloud Migration and Data Replication
Organizations migrating onto cloud platforms depend on automated pipelines to transfer and keep data in sync between on-premise databases and cloud environments. Change Data Capture (CDC) pipelines help maintain data consistency and reduce downtime during the transition.
Conclusion
Automating the data pipes is no longer a luxury; it's a must for a business that seeks to reduce the cost of data operations while enhancing efficiency and improving decision-making. Organizations can use data workflow automation to minimize manual errors as growth in source data demands scaling up and faster times to extract actionable insights.
The choice of automation solution—whether code-based for flexibility or low-code for accessibility—depends on the business requirements as well as the technical capability of the enterprise. But that alone is a part of many things that should be done in building solid, data-driven infrastructure.
The increasing volumes and growing complexity of data would mean that automation would be very important to optimize operations and realize new efficiencies. Today, investing in automated data pipelines would position companies on a steady road toward success in tomorrow's data-obsessed world.